01 Apr 2022 - AWS Big Data Blog: Build data lineage for data lakes using AWS Glue, Amazon Neptune, and Spline
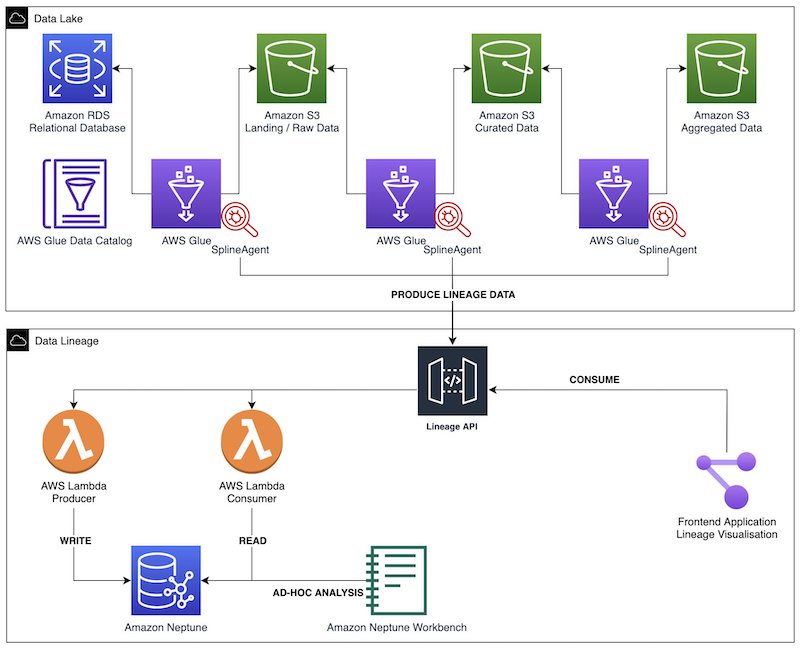
Data lineage is one of the most critical components of a data governance strategy for data lakes. Data lineage helps ensure that accurate, complete and trustworthy data is being used to drive business decisions. While a data catalog provides metadata management features and search capabilities, data lineage shows the full context of your data by capturing in greater detail the true relationships between data sources, where the data originated from and how it gets transformed and converged. Different personas in the data lake benefit from data lineage:
- For data scientists, the ability to view and track data flow as it moves from source to destination helps you easily understand the quality and origin of a particular metric or dataset
- Data platform engineers can get more insights into the data pipelines and the interdependencies between datasets
- Changes in data pipelines are easier to apply and validate because engineers can identify a job’s upstream dependencies and downstream usage to properly evaluate service impacts
As the complexity of data landscape grows, customers are facing significant manageability challenges in capturing lineage in a cost-effective and consistent manner. In this post, we walk you through three steps in building an end-to-end automated data lineage solution for data lakes: lineage capturing, modeling and storage and finally visualization.
In this solution, we capture both coarse-grained and fine-grained data lineage. Coarse-grained data lineage, which often targets business users, focuses on capturing the high-level business processes and overall data workflows. Typically, it captures and visualizes the relationships between datasets and how they’re propagated across storage tiers, including extract, transform and load (ETL) jobs and operational information. Fine-grained data lineage gives access to column-level lineage and the data transformation steps in the processing and analytical pipelines.
Author: Khoa Nguyen, Krithivasan Balasubramaniyan, and Rahul Shaurya01 Nov 2021 - Capturing & Displaying Data Transformations with Spline

How this open source tool can help automatically track & display data lineage from Apache Spark applications.
Author: Aaron Wilson04 Oct 2021 - Collecting and visualizing data lineage of Spark jobs
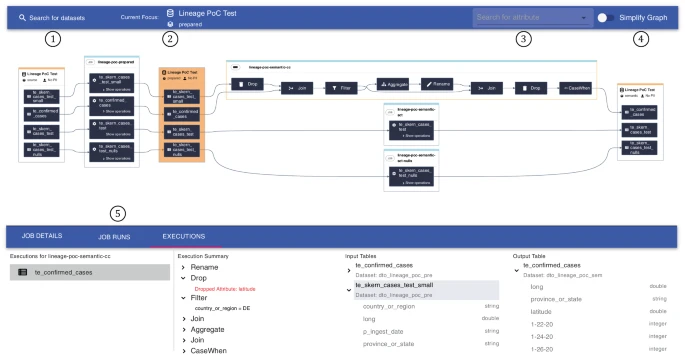
Metadata management constitutes a key prerequisite for enterprises as they engage in data analytics and governance. Today, however, the context of data is often only manually documented by subject matter experts, and lacks completeness and reliability due to the complex nature of data pipelines. Thus, collecting data lineage—describing the origin, structure, and dependencies of data—in an automated fashion increases quality of provided metadata and reduces manual effort, making it critical for the development and operation of data pipelines. In our practice report, we propose an end-to-end solution that digests lineage via (Py‑)Spark execution plans. We build upon the open-source component Spline, allowing us to reliably consume lineage metadata and identify interdependencies. We map the digested data into an expandable data model, enabling us to extract graph structures for both coarse- and fine-grained data lineage. Lastly, our solution visualizes the extracted data lineage via a modern web app, and integrates with BMW Group’s soon-to-be open-sourced Cloud Data Hub.
Author: Alexander Schoenenwald, Simon Kern, Josef Viehhauser & Johannes Schildgen22 Mar 2021 - Best Data Lineage Tools
Data is the main part of every machine learning model. Your model is only as good as the data it’s built with, and you can’t build a model at all without data. So, it makes sense to train your models only with accurate and authentic data.
In the course of running their operations, many organizations arrive at a point where they need to improve data tracking and transferring systems. This improvement might lead to:
- finding errors in the data,
- implementing effective changes to reduce risk.
- creating better data mapping systems.
Some writers say that data is the new oil. And just like oil becomes fuel for powering your car, data also has to go through a process from raw data to a model component or even a simple visualization.
Data scientists, data engineers, and Machine Learning engineers rely on data to build correct models and applications. It can help to understand the necessary journey of the data before it can be used to build accurate models.
This concept of a data journey actually has a real name — Data Lineage. In this article, we’re going to explore what data lineage means in machine learning, and see several paid and open-source data lineage tools.
Author: Ejiro Onose16 Mar 2021 - Data Lineage from Databricks to Azure Purview
At Intellishore our skilled people have found a way to make more programs compatible with Azure Purview. The integration ensures better data governance, more insights, and control of your data environments. Our goal with this blog post is to explain how to integrate data lineage from Databricks into Azure Purview and our journey to do it.
Author: Intellishore28 Sep 2020 - How We Extract Data Lineage from Large Data Warehouses

Enterprises have built massive data infrastructures to capture and manage their ever-growing mountains of data. But as data stores increase, the pipelines that carry precious information to the business become murkier, making the resulting data analysis less trustworthy. Informatica’s Enterprise Data Catalog (EDC) can help you shed light on data transformations along your pipelines, and LumenData has further built tools to extract and visualize additional data lineage to extend the use of Informatica EDC. Here’s how.
Author: Subhodip Pal And Nimish Mehta22 Jan 2020 - Data lineage tracking using Spline 0.3 on Atlas via Event Hub

Data lineage tracking is one of the critical requirements for organizations that are in highly regulated industries face. As a regulatory requirement these organizations need to have a lineage detail of how data flows through their systems. To process data, organization need fast and big data technologies. Spark is one of the popular tools. It is a unified analytics engine for big data processing, with built-in modules for streaming, SQL, machine learning and graph. While there are several products that cater to building various aspects of governance, Apache Atlas is a scalable and extensible set of core foundational governance services — enabling enterprises to effectively and efficiently meet their compliance requirements within Hadoop and allows integration with the whole enterprise data ecosystem. A connector is required to track Spark SQL/DataFrame transformations and push metadata changes to Apache Atlas. Spark Atlas Connector provides basic job information. If we need to capture attribute level transformation information within the jobs, then Spline is the another option. Spline is a data lineage tracking and visualization tool for Apache Spark. Spline captures and stores lineage information from internal Spark execution plans in a lightweight, unobtrusive and easy to use manner.
Author: Reenu Saluja @ Microsoft16 Dec 2019 - Spline 0.4 has arrived!
Updated vision and architecture
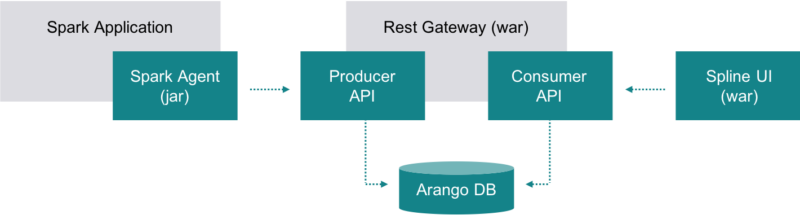
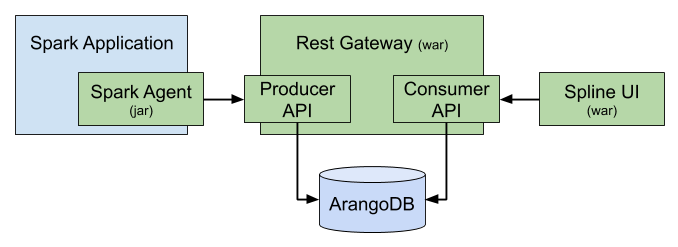
In this release we have completely revised the vision and architecture of Spline. Starting from 0.4 release Spline has begun its journey from being a simple Spark-only lineage tracking tool towards a more generic concept - a cross-framework data lineage tracking solution. The new vision covers much broader aspects of lineage tacking, including (at certain extent) real-time monitoring, errors tracking, impact analysis and many more. Spline version 0.4.0 is the first version of that “new” Spline. It doesn’t contain any brand-new features so far comparing to Spline 0.3.9, but it rather provides a brand-new background and architecture.
See Spline 0.4.0 release notes for details.
Author: Oleksandr Vayda @ ABSA20 Nov 2019 - Spark Data Lineage on Databricks Notebook using Spline
Apache Spark has become the de facto unified engine for analytical workloads in the Big Data world. As we all know, Spark extends the popular MapReduce model to efficiently support more types of computations, including interactive queries and stream processing. One of the main features Spark offers for speed is the ability to run computations in memory. Spline is derived from the words Spark and Lineage. It is a tool which is used to visualize and track how the data changes over time. Spline provides a GUI where the user can view and analyze how the data transforms to give rise to the insights.
Author: Akshay Shankar14 Apr 2019 - Data Lineage In Azure Databricks With Spline
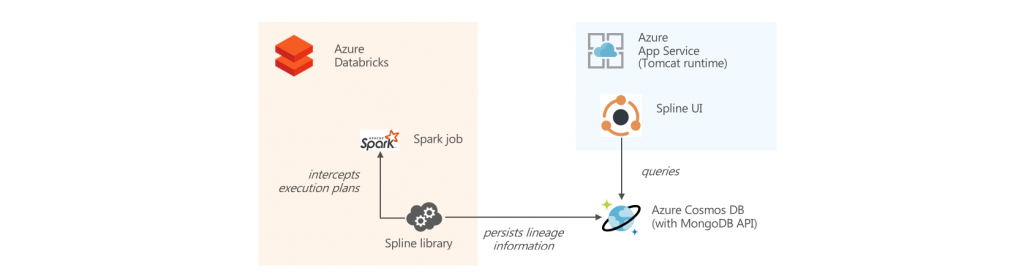
The Spline open-source project can be used to automatically capture data lineage information from Spark jobs, and provide an interactive GUI to search and visualize data lineage information. We provide an Azure DevOps template project that automates the deployment of an end-to-end demo project in your environment, using Azure Databricks, Cosmos DB and Azure App Service.
Author: Alexandre Gattiker25 Mar 2019 - Spark job lineage in Azure Databricks with Spline and Azure Cosmos DB API for MongoDB

iTracking lineage of data as it is manipulated within Apache Spark is a common ask from customers. As of date, there are two options, the first of which is the Hortonworks Spark Atlas Connector, which persists lineage information to Apache Atlas. However, some customers who use Azure Databricks do not necessarily need or use the “full” functionality of Atlas, and instead want a more purpose-built solution. This is where the second option, Spline, comes in. Spline can persist lineage information to Apache Atlas or to a MongoDB database. Now, given that Azure Cosmos DB exposes a MongoDB API, it presents an attractive PaaS option to serve as the persistence layer for Spline.
Author: Arvind Shyamsundar @ Microsoft24 Jan 2019 - Atlas Support Is Back!
Apache Atlas is meta data management platform for big data, which is often also used for data lineage. Spline support of Atlas was temporarily removed due to large refactoring on version 0.3. But now Atlas support is back thanks to Marek Novotny released in 0.3.6. Supported Atlas version now is 1.0.
Spline Atlas Integration vs Hortonworks Spark Atlas Connector
Those who need to use Atlas only and are not worried about loosing Spline’s UI closely tailored for data lineage and improved lineage linking (Spline links exact file versions that were used) may consider using also Hortonworks Spark Atlas connector.
In short differences between these tools are:
- Spline captures attribute level transformation information within the jobs while Hortonworks provides only basic job information
- Spline doesn’t support ML and Hive data lineages
How To Try Out Spline Atlas Integration
- Download Hortonworks Data Platform 3.0.1 Virtualbox Image.
- Install VirtualBox.
- Import image into virtualbox with default settings.
- Change password via via browser ssh simulator on http://localhost:4200/ from
hadoopto e.g.splineisgr8t. Alternatively you can accesssandbox-hdpviassh root@localhost -p 2201. - Run
ambari-admin-password-reset. After password change Ambari will start. Close the ssh channel. - Go to http://localhost:8080 and make sure HBase, Atlas, Infra Solr, Kafka, HDFS, YARN have maintanence mode disabled and are started
- Change password in Atlas’ advanced configs tab and restart it and verify that you can access it on http://localhost:21000
- SSH into
sandbox-hostwithssh root@localhost -p 2122using passwordhadoop - Proxy additional port 6667 akin to other records:
vi /sandbox/proxy/conf.stream.d/tcp-hdp.conf - Deploy proxy config
/sandbox/proxy/proxy-deploy.shand exit ssh channel. - Secure copy spline meta model json file from Spline source:
scp -P 2201 spline/persistence/atlas/src/main/atlas/spline-meta-model.json root@localhost:/usr/hdp/current/atlas-server/models/ - Go to Ambari and restart Atlas
- Make sure that you can set
Search By Typetospark_job - Configure your
/etc/hostsfile:127.0.0.1 localhost sandbox-hdp.hortonworks.com sandbox-hdp - In Spline source code configure Sample jobs properties file:
sample/src/main/resources/spline.properties:spline.persistence.factory=za.co.absa.spline.persistence.atlas.AtlasPersistenceFactory atlas.kafka.bootstrap.servers=localhost:6667 atlas.kafka.hook.group.id=atlas atlas.kafka.zookeeper.connect=localhost:2181 - Run a sample job e.g.
/sample/src/main/scala/za/co/absa/spline/sample/batch/SampleJob1.scala - Search Atlas setting
Search By Typetospark_joband you should be able to find your lineage
24 Dec 2018 - Exploring the Spline Data Tracker and Visualization tool for Apache Spark (Part 2)
In part 1 we have learned how to test data lineage info collection with Spline from a Spark shell. The same can be done in any Scala or Java Spark application. The same dependencies for the Spark shell need to be registered in your build tool of choice (Maven, Gradle or sbt) …
Author: Guglielmo Iozzia @ Optum Ireland02 Dec 2018 - Exploring the Spline Data Tracker and Visualization tool for Apache Spark (Part 1)
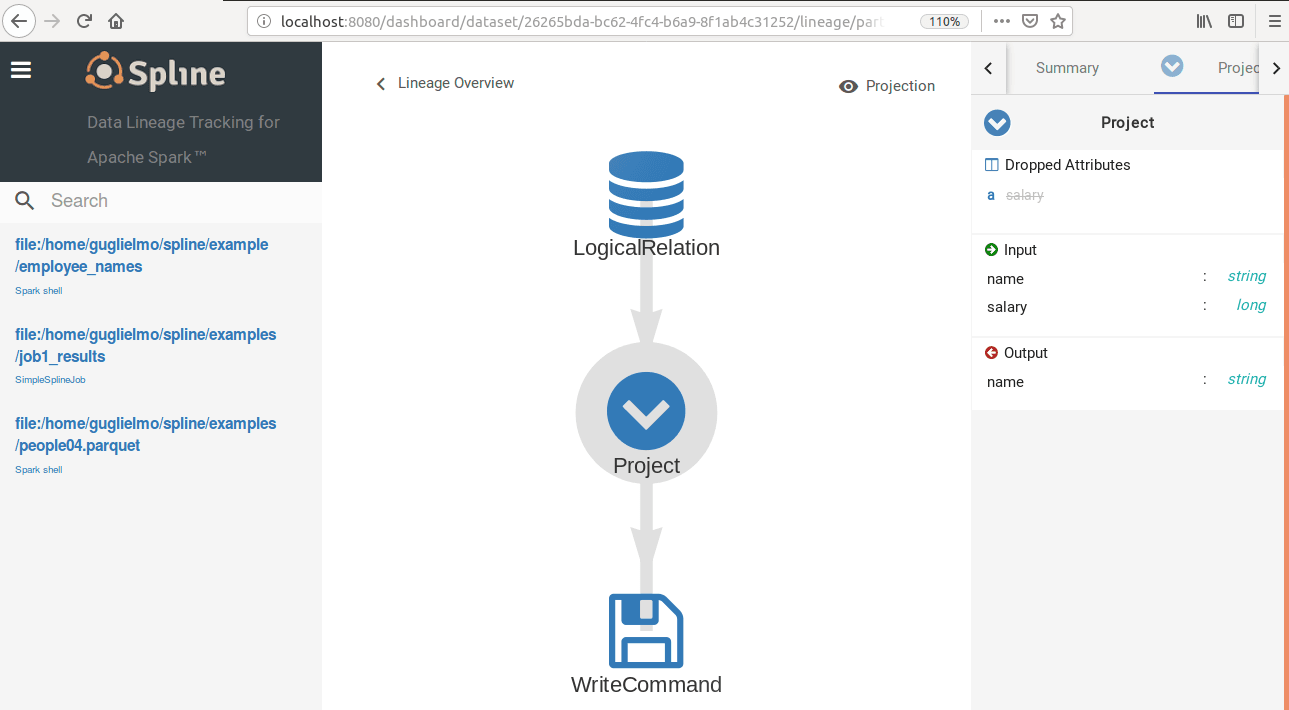
One interesting and promising Open Source project that caught my attention lately is Spline, a data lineage tracking and visualization tool for Apache Spark, maintained at Absa. This project consists of 2 parts: a Scala library that works on the drivers which, by analyzing the Spark execution plans, captures the data lineages and a web application which provides a UI to visualize them.
Author: Guglielmo Iozzia @ Optum Ireland30 Nov 2018 - Spline 2: Vision And Architecture Overview
Upcoming Spline changes:
- EventBus for client-server separation
- Graph DB for query performance and more natural data model via ArangoDB
25 Oct 2018 - Spline 0.3 User Guide
Guides through basic UI features of Spline v0.3.
Author: Vaclav Kosar @ ABSA04 Oct 2018 - Spline: Data Lineage For Spark Structured Streaming
Data lineage tracking is one of the significant problems that companies in highly regulated industries face. These companies are forced to have a good understanding of how data flows through their systems to comply with strict regulatory frameworks. Many of these organizations also utilize big and fast data technologies such as Hadoop, Apache Spark and Kafka. Spark has become one of the most popular engines for big data computing. In recent releases, Spark also provides the Structured Streaming component, which allows for real-time analysis and processing of streamed data from many sources. Spline is a data lineage tracking and visualization tool for Apache Spark. Spline captures and stores lineage information from internal Spark execution plans in a lightweight, unobtrusive and easy to use manner.
Additionally, Spline offers a modern user interface that allows non-technical users to understand the logic of Apache Spark applications. In this presentation we cover the support of Spline for Structured Streaming and we demonstrate how data lineage can be captured for streaming applications.
Presented at Spark + AI Summit London 2018
Author: Vaclav Kosar, Marek Novotny @ ABSA18 Apr 2018 - Zeenea - Data lineage : Comment cartographier ses données au sein de son SI ?

16 Apr 2018 - End to End Atlas Lineage with Nifi, Spark, Hive

Capturing lineage with Atlas from Nifi, Spark and Hive by solving the gap mentioned above using Spline. Spline captures and stores lineage information from internal Spark execution plans in a lightweight, unobtrusive (even if there is an issue in lineage generation , spark job will not fail ) and easy to use manner. …
Author: Sreekanth Munigati @ Hortonworks19 Feb 2018 - Data Lineage sur Apache Spark avec Spline
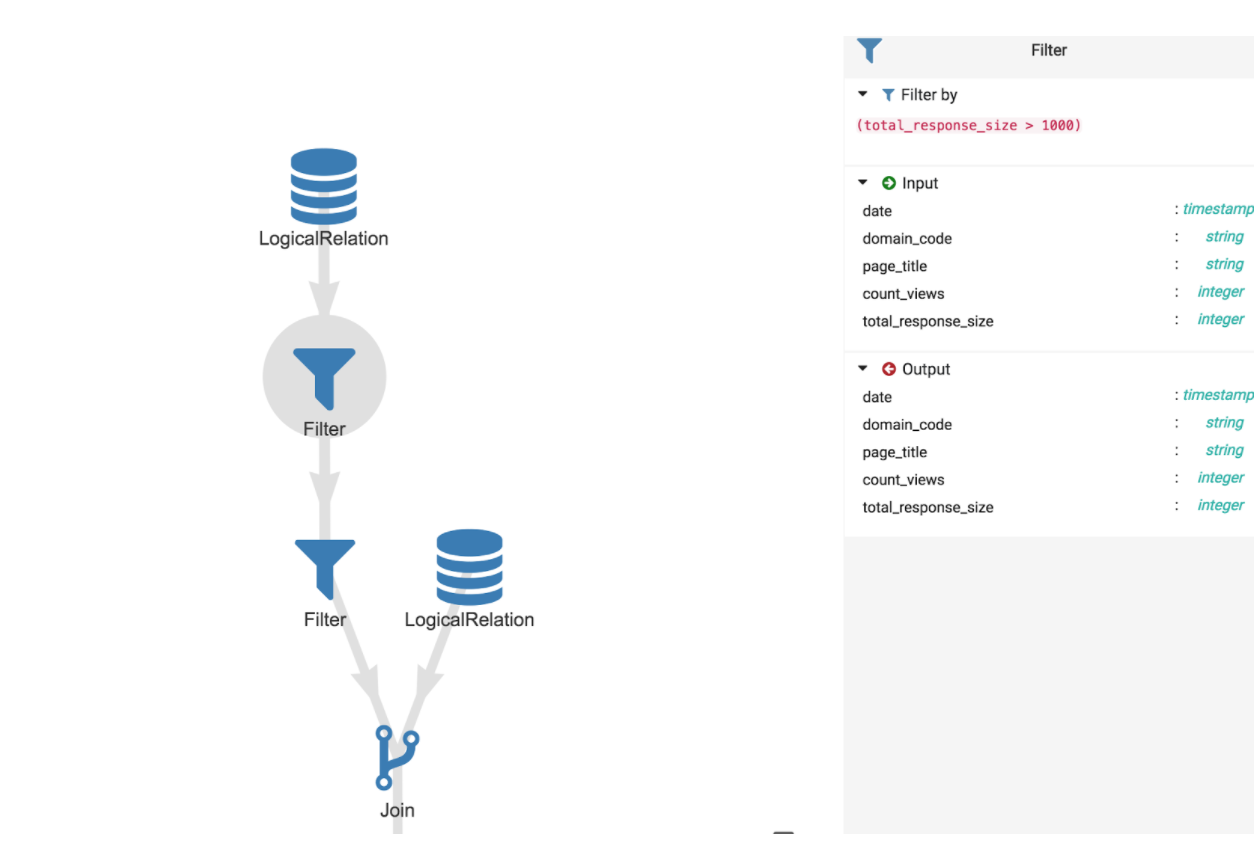
Hormis cela, Spline est un outil facile à prendre en main et avec une UI de qualité qui permet aux développeurs et aux métiers d’échanger et d’interagir sur une base commune. À surveiller car Spline est un outil encore jeune qui va s’améliorer et s’enrichir de nouvelle fonctionnalités au cours du temps (Spark Streaming, versionning plus fin des dataset IO, gestion des utilisateurs qui lance les jobs…)…
Author: Lucien Fregosi @ Natixis05 Feb 2018 - Data Lineage Tracking and Visualization tool for Apache Spark

The work of a data engineer typically consists of making code (received from data analysts or data scientists) ready for production. This means it runs on Apache Spark and the code is scalable. Once the code is in production, the data engineers move on to a different task. The code written typically involves a lot of number-crunching. As time passes (weeks or months even), people analyzing the numbers come with questions on how the numbers are calculated. This becomes an impossible task for a data engineer. Hence, tools are necessary that can do this.
The process of keeping track of and visualizing the data manipulation is called data lineage. Not only is this useful for people working with the data, but with legal regulations like GDPR coming in May 2018, this will become a must. For financial institutions data lineage is one of the most significant problems when using big data tools. Mostly because they are obligated to have transparent reports, and to show how numbers are being derived. In order to make this process more streamlined, a team of developers at the Barclays Africa Group Limited have developed a tool that integrates into Apache Spark: Spline (Spark Lineage). This is what we will be discussing in this article.
Author: Alper Topcuoglu17 Jan 2018 - Spline: Spark Lineage, Not Only for the Banking Industry
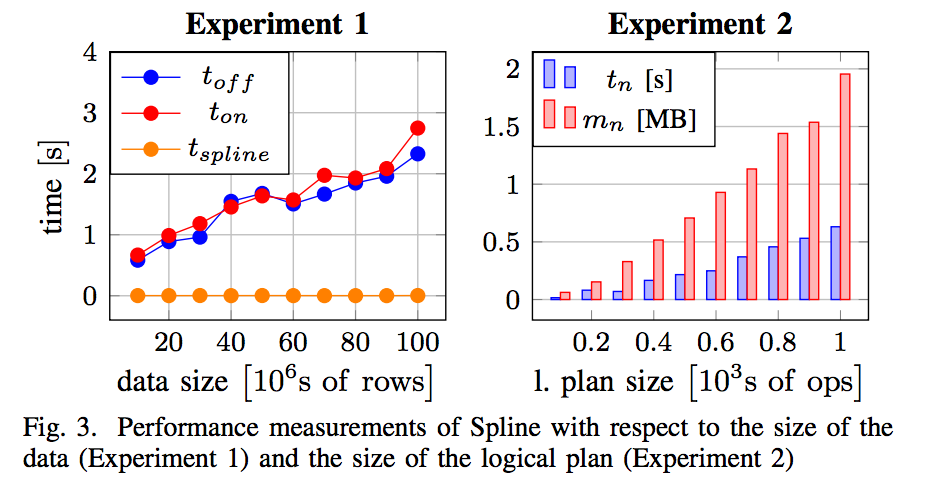
Data lineage tracking is one of the significant problems that financial institutions face. Banking and other highly regulated industries are forced to have a good understanding of how data flows through their systems to comply with strict regulatory frameworks. Many of these organizations also utilize big data technologies such as Hadoop and Apache Spark. Spark has become one of the most popular engines for big data computation, but it lacks support for data lineage tracking.
This paper describes Spline - a data lineage tracking and visualization tool for Apache Spark. Spline captures and stores lineage information from internal Spark execution plans in a lightweight, unobtrusive and easy to use manner. Additionally, Spline offers a modern user interface that allows non-technical users to understand the logic of Apache Spark applications. Keywords—Spline; Apache Spark; data lineage; Big data applications; Apache Hadoop; banking; BCBS
Author: Jan Scherbaum, Marek Novotny, Oleksandr Vayda @ ABSA24 Oct 2017 - Spline: Apache Spark Lineage, Not Only for the Banking Industry
Data lineage tracking is one of the significant problems that financial institutions face when using modern big data tools. This presentation describes Spline – a data lineage tracking and visualization tool for Apache Spark. Spline captures and stores lineage information from internal Spark execution plans and visualizes it in a user-friendly manner.
Presented at Spark Summit Europe 2017
Author: Jan Scherbaum, Marek Novotny @ ABSA