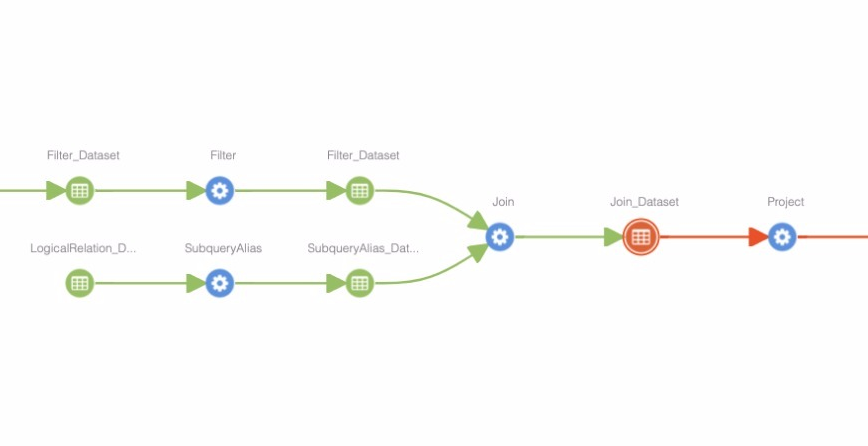
Apache Atlas is meta data management platform for big data, which is often also used for data lineage. Spline support of Atlas was temporarily removed due to large refactoring on version 0.3. But now Atlas support is back thanks to Marek Novotny released in 0.3.6. Supported Atlas version now is 1.0.
Spline Atlas Integration vs Hortonworks Spark Atlas Connector
Those who need to use Atlas only and are not worried about loosing Spline’s UI closely tailored for data lineage and improved lineage linking (Spline links exact file versions that were used) may consider using also Hortonworks Spark Atlas connector.
In short differences between these tools are:
- Spline captures attribute level transformation information within the jobs while Hortonworks provides only basic job information
- Spline doesn’t support ML and Hive data lineages
How To Try Out Spline Atlas Integration
- Download Hortonworks Data Platform 3.0.1 Virtualbox Image.
- Install VirtualBox.
- Import image into virtualbox with default settings.
- Change password via via browser ssh simulator on http://localhost:4200/ from
hadoopto e.g.splineisgr8t. Alternatively you can accesssandbox-hdpviassh root@localhost -p 2201. - Run
ambari-admin-password-reset. After password change Ambari will start. Close the ssh channel. - Go to http://localhost:8080 and make sure HBase, Atlas, Infra Solr, Kafka, HDFS, YARN have maintanence mode disabled and are started
- Change password in Atlas’ advanced configs tab and restart it and verify that you can access it on http://localhost:21000
- SSH into
sandbox-hostwithssh root@localhost -p 2122using passwordhadoop - Proxy additional port 6667 akin to other records:
vi /sandbox/proxy/conf.stream.d/tcp-hdp.conf - Deploy proxy config
/sandbox/proxy/proxy-deploy.shand exit ssh channel. - Secure copy spline meta model json file from Spline source:
scp -P 2201 spline/persistence/atlas/src/main/atlas/spline-meta-model.json root@localhost:/usr/hdp/current/atlas-server/models/ - Go to Ambari and restart Atlas
- Make sure that you can set
Search By Typetospark_job - Configure your
/etc/hostsfile:127.0.0.1 localhost sandbox-hdp.hortonworks.com sandbox-hdp - In Spline source code configure Sample jobs properties file:
sample/src/main/resources/spline.properties:spline.persistence.factory=za.co.absa.spline.persistence.atlas.AtlasPersistenceFactory atlas.kafka.bootstrap.servers=localhost:6667 atlas.kafka.hook.group.id=atlas atlas.kafka.zookeeper.connect=localhost:2181 - Run a sample job e.g.
/sample/src/main/scala/za/co/absa/spline/sample/batch/SampleJob1.scala - Search Atlas setting
Search By Typetospark_joband you should be able to find your lineage