Spline (from Spark lineage) project helps people get insight into data processing performed by Apache Spark ™
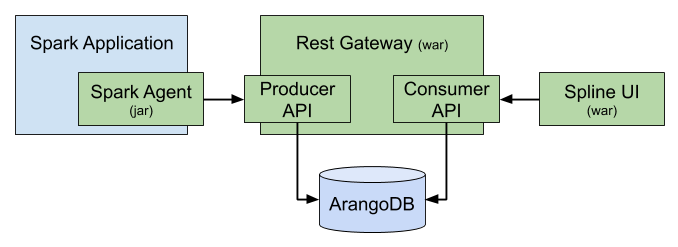
The project consists of three main parts:
-
Spark Agent that sits on drivers, capturing the data lineage from Spark jobs being executed by analyzing the execution plans
-
Rest Gateway, that receive the lineage data from agents and stores it in the database
-
Web UI application that visualizes the stored data lineages
There are several other tools. Check the examples to get a better idea how to use Spline.
Other docs/readme files can be found at:
Motivation
Spline aims to fill a big gap within the Apache Hadoop ecosystem. Spark jobs shouldn’t be treated only as magic black boxes; people should be able to understand what happens with their data. Our main focus is to solve the following particular problems:
-
Regulatory requirements for SA banks (BCBS 239)
By 2020, all South African banks will have to be able to prove how numbers are calculated in their reports to the regulatory authority.
-
Documentation of business logic
Business analysts should get a chance to verify whether Spark jobs were written according to the rules they provided. Moreover, it would be beneficial for them to have up-to-date documentation where they can refresh their knowledge of a project.
-
Identification of performance bottlenecks
Our focus is not only business-oriented; we also see Spline as a development tool that should be able to help developers with the performance optimization of their Spark jobs.
Getting started
TL;DR
Spin up a Spline server in a Docker
wget https://raw.githubusercontent.com/AbsaOSS/spline-getting-started/main/docker/docker-compose.yml
wget https://raw.githubusercontent.com/AbsaOSS/spline-getting-started/main/docker/.env
docker-compose up
Run you Spark-shell or PySpark as below to enable lineage tracking:
(NOTE: we use Spline Agent bundle compiled for Spark 2.4 and Scala 2.12. For other Spark or Scala versions use corresponding bundles)
pyspark \
--packages za.co.absa.spline.agent.spark:spark-2.4-spline-agent-bundle_2.12:0.5.6 \
--conf "spark.sql.queryExecutionListeners=za.co.absa.spline.harvester.listener.SplineQueryExecutionListener" \
--conf "spark.spline.producer.url=http://localhost:9090/producer"
Execute any of your Spark Job that writes to a persistent storage (like file, Hive table or a database). The lineage should be captured automatically.
Open http://localhost:8080 in your browser to see the captured lineage.
See also - https://github.com/AbsaOSS/spline-getting-started
Step-by-step instructions
Get Spline components
First, you need to get a minimal set of Spline’s moving parts - a server, an admin tool and a client Web UI to see the captured lineage.
Download prebuild Spline artifacts from the Maven repo
za.co.absa.spline:admin:0.5.6za.co.absa.spline:rest-gateway:0.5.6za.co.absa.spline.ui:spline-web-ui:0.5.7za.co.absa.spline:client-web:0.5.6
(REST Server and Web Client modules are also available as Docker containers)
Build Spline from the source code
Note: Skip this section unless you want to hack with Spline
-
Make sure you have JDK 8+ and Maven 3.5+
- Get and unzip the Spline source code:
wget https://github.com/AbsaOSS/spline/archive/release/0.5.6.zip unzip 0.5.6.zip - Change the directory:
cd spline-release-0.5.6 - Run the Maven build:
mvn install -DskipTests
Create Spline Database
Spline server requires ArangoDB to run.
Please install ArangoDB 3.7.3 or later according to the instructions in ArangoDB documentation.
Or if you prefer the Docker way there is a ArangoDB docker image as well.
docker run -p 8529:8529 -e ARANGO_NO_AUTH=1 arangodb/arangodb:3.7.3
Once your database is running you should be able to see ArangoDB web interface at http://localhost:8529.
Next you need to create a Spline database using Spline Admin tool.
java -jar admin-0.5.6.jar db-init arangodb://localhost/spline
Start Spline Server
Use one of the following options depending on your deployment preferences:
Docker container
docker container run \
-e spline.database.connectionUrl=arangodb://host.docker.internal/spline \
-p 8080:8080 \
absaoss/spline-rest-server:0.5.6
Note for Linux: If host.docker.internal does not resolve replace it with 172.17.0.1 (see Docker for-linux bug report)
Java compatible Web-Container (e.g. Tomcat)
Download a WAR-file using the link below, and deploy it into any J2EE-compatible Web Container, e.g. Tomcat, Jetty, JBoss etc.
za.co.absa.spline:rest-gateway:0.5.6
Spline server requires configuring an ArangoDB connection string.
The WAR-file provides several alternative ways how to set configuration parameters:
-
JNDI
(for example in a
context.xmlin the Tomcat server)<Environment type="java.lang.String" name="spline/database/connectionUrl" value="arangodb://localhost/spline" /> - JVM property
$JAVA_OPTS -Dspline.database.connectionUrl=arangodb://localhost/spline - System environment variable
export SPLINE_DATABASE_CONNECTION_URL=arangodb://localhost/spline
Verify Spline Server
Open the server root URL in you browser: http://localhost:8080/
You should see a dashboard with the updating server status information, server version, exposed API and some other useful info.
The server exposes the following REST API:
- Producer API (
/producer/*) - Consumer API (
/consumer/*)
… and other useful URLs:
- Running server version information: /about/version
- Producer API Swagger documentation: /docs/producer.html
- Consumer API Swagger documentation: /docs/consumer.html
Start Spline UI
Just like the other Spline component you can choose if you want to use a Docker container or a WAR-file.
Docker
docker container run \
-e SPLINE_CONSUMER_URL=http://localhost:8080/consumer \
-p 9090:8080 \
absaoss/spline-web-client:0.5.6
Java compatible Web-Container (e.g. Tomcat)
You can find the WAR-file of the Web Client in the repo here:
za.co.absa.spline:client-web:0.5.6
Add the argument for the Consumer URL (the same 3 configuration options are available as for the REST Gateway above - JNDI, JVM properties and environment variable)
-Dspline.consumer.url=http://localhost:8080/consumer
Open Spline Web UI in the browser
http://localhost:9090
Capture some lineage
At this point you have your Spline server with the UI up and running and ready for lineage tracking. The way to do it depends on the tool or framework you are using for processing your data. Spline has started as a Apache Spark lineage tracking tool, and although it’s gradually evolving into a generic lineage tracking solution that can be used with other data processing frameworks and tools, it’s still works the best with Apache Spark.
The simplest way to track Apache Spark lineage is to enable it in you spark-submit or pyspark command line as shown in the tl;dr section.
If you want to have a fine control on Spline, customize or extend some of its components you can embed Spline as a component into your own Spark application.
Embed Spline in your Spark application
Add a dependency on the Spline Spark agent core.
<dependency>
<groupId>za.co.absa.spline.agent.spark</groupId>
<artifactId>agent-core_2.11</artifactId>
<version>0.5.6</version>
</dependency>
(for Scala 2.12 use agent-core_2.12 respectively)
In your Spark job enable lineage tracking.
// given a Spark session ...
val sparkSession: SparkSession = ???
// ... enable data lineage tracking with Spline
import za.co.absa.spline.harvester.SparkLineageInitializer._
sparkSession.enableLineageTracking()
// ... then run some Dataset computations as usual.
// The lineage will be captured and sent to the configured Spline Producer endpoint.
Properties
You also need to set some configuration properties. Spline combines these properties from several sources:
-
Hadoop config (
core-site.xml) -
JVM system properties
-
spline.propertiesfile in the classpath
spline.mode
-
DISABLEDLineage tracking is completely disabled and Spline is unhooked from Spark. -
REQUIREDIf Spline fails to initialize itself (e.g. wrong configuration, no db connection etc) the Spark application aborts with an error. -
BEST_EFFORT(default) Spline will try to initialize itself, but if fails it switches to DISABLED mode allowing the Spark application to proceed normally without Lineage tracking.
spline.producer.url
- url of spline producer (part of rest gateway responsible for storing lineages in database)
Example:
spline.mode=REQUIRED
spline.producer.url=http://localhost:8080/producer
Upgrade Spline database
Upgrade from any Spline 0.4+ to the latest version
java -jar admin-0.5.6.jar db-upgrade arangodb://localhost/spline
Upgrade from Spline 0.3 to 0.4
Spline 0.3 stored data in the MongoDB. Spline 0.4 uses ArangoDB instead. You need to use another tool for migrating data between those two databases - Spline Migrator
You also need to have a new Spline server running. The migrator tool will fetch the data directly from a MongoDB, convert it and send to a new Spline Producer REST endpoint.
java -jar migrator-tool-0.4.2.jar \
--source=mongodb://localhost:27017/splinedb \
--target=http://localhost:8080/spline/producer
Also run java -jar migrator-tool-0.4.2.jar --help to read about usage and available options.
For more information you may take a look at the Migrator tool source code.
Copyright 2019 ABSA Group Limited
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.