Spline is a free and open-source tool for automated tracking data lineage and data pipeline structure in your organization.
Originally the project was created as a lineage tracking tool specifically for Apache Spark ™ (the name Spline stands for Spark Lineage). In 2018, the IEEE Paper has been published. Later though, the vision of the project was expanded, and the system design was generalized to accommodate other data technologies, not only Spark.
The goal of the project is to create a simple but capable cross-platform and cross-framework data-lineage tracking solution that could be used along, or serve as a foundation for building more advanced data governance solutions on top of it.
At a high-level, the project consists of three main parts:
- Spline Server
- Spline Agents:
- Apache Spark agent – for Scala, Python or Spark SQL dialect
- Python agent – for arbitrary functions written in Python 3.9+
- Open-Lineage adapter (PoC) – for importing metadata in OpenLineage API format.
- Spline UI
The Spline Server is the heart of Spline. It receives the lineage data from agents via Producer API and stores it in the ArangoDB. On the other end It provides Consumer API for reading and querying the lineage data. Consumer API is used by Spline UI, but can also be used by 3rd party applications.
The agents capture the lineage meta-data form the data-transformation pipelines and send it to the Spline server in a standardized format via a cross-platform API (called Producer API) using HTTP (REST) or Kafka as transport.
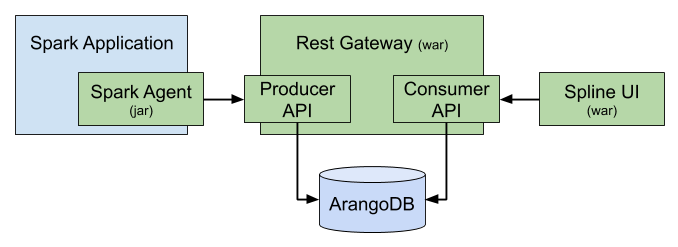
The lineage data is then processed and stored in a graph format, and is accessible via another REST API (called Consumer API).
Table of Contents
Motivation
Our main focus is to solve the following particular problems:
-
Regulatory requirements (BCBS 239, GDPR etc)
-
Documentation of business logic
Business analysts should get a chance to verify whether jobs were written according to the rules they provided. Moreover, it would be beneficial for them to have up-to-date documentation where they can refresh their knowledge of a project.
-
Identification of performance bottlenecks
Our focus is not only business-oriented; we also see Spline as a development tool that should be able to help developers with the performance optimization of their Spark jobs.
Getting started
TL;DR
We have created a Docker-compose config (see Spline getting started) to help you to get Spline up and running in just a few keystrokes. So if you only have 5 minutes to try Spline out then simply do the following:
wget https://raw.githubusercontent.com/AbsaOSS/spline-getting-started/main/docker/docker-compose.yml
wget https://raw.githubusercontent.com/AbsaOSS/spline-getting-started/main/docker/.env
docker-compose up
That will spin up a few Docker containers (ArangoDB, Spline Server and Spline UI), and run a set of Spark examples to pre-populate the database.
Open http://localhost:9090 in the browser to see the Spline UI and captured example lineage data.
The Spline server is running on http://localhost:8080
Now you can run your tracked job implemented in Python, or Apache Spark (spark-shell, pyspark or spark-submit) with lineage tracking enabled
and immediately see the result in the Spline UI.
Python example
First, decorate you Python code that you want to track with the Spline Agent decorators. At minimum, you need to specify the entry point function (a top-level function that will be tracked) and the input and output datasource URIs (for the purpose of tracking lineage).
my-example-app.py:
import spline_agent
from spline_agent.enums import WriteMode
@spline_agent.track_lineage(name = "My Awesome Python Job")
def my_example_func():
# read some files, do stuff, write the result
_read_from("hdfs://..../input.csv")
_write_to("s3://..../output.csv")
@spline_agent.inputs('{url}')
def _read_from(url: str) -> SomeData:
# do actual read
return data
@spline_agent.output('{url}', WriteMode.OVERWRITE)
def _write_to(url: str, payload: SomeData):
# do actual write
pass
then, install Spline Agent library, configure it, and execute your Python app as usual.
# install "spline-agent" library
pip install spline-agent
# configure the Spline Agent to send captured lineage metadata to the Spline Producer REST API
export SPLINE_LINEAGE_DISPATCHER_TYPE=http
export SPLINE_LINEAGE_DISPATCHER_HTTP_BASE_URL=http://localhost:8080/producer
# execute the Python app. The lineage will captured and sent to the Spline server.
python my-example-app.py
Spark example
# Start the "pyspark" shell (or we can use "spark-shell" or "spark-submit" in the same way)
# with lineage tracking enabled automatically for any execute Spark job.
pyspark \
--packages za.co.absa.spline.agent.spark:spark-3.0-spline-agent-bundle_2.12:2.2.0 \
--conf "spark.sql.queryExecutionListeners=za.co.absa.spline.harvester.listener.SplineQueryExecutionListener" \
--conf "spark.spline.producer.url=http://localhost:8080/producer"
Note: By default, only persistent writes are tracked (like write to a file, Hive table or a database).
Note: In the example above we used Spline Agent bundle compiled for Spark 3.0 and Scala 2.12. For other Spark and Scala versions use corresponding bundles. See selecting agent artifacts for details.
Also see Spline getting started
Step-by-step instructions
Get Spline components
All Spline components are available as J2EE artifacts (JAR or WAR-files) as well as Docker containers:
Choose what suites you better.
Docker containers are hosted on Docker Hub:
- absaoss/spline-admin:0.7.9
- absaoss/spline-rest-server:0.7.9
- absaoss/spline-kafka-server:0.7.9
- absaoss/spline-web-ui:0.7.5
- absaoss/spline-spark-agent:2.2.0 (contains examples)
J2EE artifacts can be found on Maven Central:
- za.co.absa.spline:admin:0.7.9
- za.co.absa.spline:rest-gateway:0.7.9
- za.co.absa.spline:kafka-gateway:0.7.9
- za.co.absa.spline.ui:spline-web-ui:0.7.5
Python agent is on available on PyPI:
Create Spline Database
Spline server requires ArangoDB to run.
Please install ArangoDB version 3.11 or newer according to the instructions in ArangoDB documentation.
Example:
docker run -p 8529:8529 -e ARANGO_NO_AUTH=1 arangodb:3.11
Once the database server is running you should be able to see ArangoDB Web UI at http://localhost:8529
Next, create a Spline database using Spline Admin utility:
docker run -it --rm absaoss/spline-admin:0.7.9 db-init arangodb://172.17.0.1/spline
Detailed usage documentation can be seen by running the Admin tool with the --help parameter:
docker run -it --rm absaoss/spline-admin:0.7.9 --help
Start Spline Server
docker container run \
-e SPLINE_DATABASE_CONNECTION_URL=arangodb://host.docker.internal/spline \
-p 8080:8080 \
absaoss/spline-rest-server:0.7.9
Optionally, you may also start Spline Kafka Gateway if you plan to use Kafka transport for your agents.
See Spline Kafka for details.
docker container run \
-e SPLINE_DATABASE_CONNECTION_URL=arangodb://host.docker.internal/spline \
-e spline.kafka.consumer.bootstrap.servers=localhost:9092 \
-e spline.kafka.consumer.group.id=spline-group \
-e spline.kafka.topic=spline-topic \
-p 7070:8080 \
absaoss/spline-kafka-server:0.7.9
Note for Linux users: If host.docker.internal does not resolve replace it with 172.17.0.1 (see Docker for-linux bug report)
Configuration
-
SPLINE_DATABASE_CONNECTION_URLURL to the ArangoDB database. (See Admin tool help)
-
SPLINE_DATABASE_LOG_FULL_QUERY_ON_ERRORUseful for development and debugging purposes. It controls the AQL log verbosity in case of errors. Set it to
trueif you want the full AQL query to be logged. (Default isfalse- only a part of the query is logged). -
SPLINE_DATABASE_DISABLE_SSL_VALIDATIONShould validation of self-signed SSL certificates be disabled.
true- SSL validation is disabled (Don’t use on production).false- enabled (Default). -
spline.kafka.topicA topic from which the gateway should consume messages.
-
spline.kafka.consumer.*A prefix for standard kafka consumer properties. Kafka gateway uses standard Kafka consumer inside, so any of it’s confiuration properties can be used after this prefix.
For example
spline.kafka.consumer.bootstrap.serversorspline.kafka.consumer.group.id.
Check Spline Server status
Open the server URL in the browser: http://localhost:8080
You should see a dashboard with the updating server status information, server version, exposed API and some other useful info.
The Spline REST server exposes the following REST APIs:
- Producer API (
/producer/*) - Consumer API (
/consumer/*)
… and other useful URLs:
- Running server version information: /about/version
- Producer API Swagger documentation: /docs/producer.html
- Consumer API Swagger documentation: /docs/consumer.html
Start Spline UI
docker container run \
-e SPLINE_CONSUMER_URL=http://localhost:8080/consumer \
-p 9090:8080 \
absaoss/spline-web-ui:0.7.5
Open Spline Web UI in the browser: http://localhost:9090
See Spline UI Readme for details.
Capture some lineage
Refer to the Spline agent for Spark for detailed explanation how Spline agent is used to capture lineage from Spark jobs.
Also see Examples page, where you can find examples of generic (non-Spark) lineage capturing, by directly calling Spline Producer API.
Running Spline as Java application
Although Docker is the preferred and the most convenient way of running Spline, you can also run it on standard Java environment.
The admin tool:
java -jar admin-0.7.9.jar db-init arangodb://localhost/spline
The REST server:
Download the WAR-file using the link below, and deploy it onto any J2EE-compatible Web Container, e.g. Tomcat, Jetty, JBoss etc.
za.co.absa.spline:rest-gateway:0.7.9
Spline Web application is looking for configuration in the following sources (in order of precedence):
-
Naming and directory context (via JNDI) if available
(for example in a
context.xmlin the Tomcat server)<Environment type="java.lang.String" name="spline/database/connectionUrl" value="arangodb://localhost/spline" /> - JVM system properties
$JAVA_OPTS -Dspline.database.connectionUrl=arangodb://localhost/spline - System environment variables
export SPLINE_DATABASE_CONNECTION_URL=arangodb://localhost/spline
Please adhere to the naming convention of each configuration source type. For example, the property foo.barBaz would be looked up as foo.barBaz in the JVM options, as foo/barBaz in the JNDI, and as FOO_BAR_BAZ in the environment variables.
The Web UI:
See Spline UI - Running a WAR-file
Upgrade Spline database
Upgrade from any Spline version greater than 0.4 to the latest version
docker run -it --rm absaoss/spline-admin:0.7.9 db-upgrade <SPLINE_DB_URL>
… or if you prefer Java
java -jar admin-0.7.9.jar db-upgrade <SPLINE_DB_URL>
Note: Depending on your database size, migration procedure (especially from 0.5 to 0.6) can consume significant amount of memory on the ArangoDB server. It’s recommended to preliminary increase RAM size (e.g. at least 128Gb for a database with average 500K records per collection). When migration is complete, RAM can be returned to its normal size.
Note: There is no automatic rollback for database migration! If migration fails for any reason you should start over from the clean database snapshot. So don’t forget to make backups before running the migration tool!
Upgrade from Spline 0.3
Spline 0.3 stored data in the MongoDB. Starting from version 0.4 further Spline uses ArangoDB instead. You need to use another tool for migrating data between those two databases - Spline Migrator
You also need to have a new Spline server running. The migrator tool will fetch the data directly from a MongoDB, convert it and send to a new Spline Producer REST endpoint.
java -jar migrator-tool-0.4.2.jar \
--source=mongodb://localhost:27017/splinedb \
--target=http://localhost:8080/producer
Also run java -jar migrator-tool-0.4.2.jar --help to read about usage and available options.
For more information you may take a look at the Migrator tool source code.
Copyright 2019 ABSA Group Limited
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.