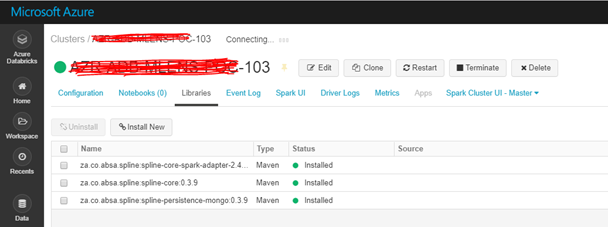
Apache Spark has become the de facto unified engine for analytical workloads in the Big Data world. As we all know, Spark extends the popular MapReduce model to efficiently support more types of computations, including interactive queries and stream processing. One of the main features Spark offers for speed is the ability to run computations in memory. Spline is derived from the words Spark and Lineage. It is a tool which is used to visualize and track how the data changes over time. Spline provides a GUI where the user can view and analyze how the data transforms to give rise to the insights.