Data lineage is one of the most critical components of a data governance strategy for data lakes. Data lineage helps ensure that accurate, complete and trustworthy data is being used to drive business decisions. While a data catalog provides metadata management features and search capabilities, data lineage shows the full context of your data by capturing in greater detail the true relationships between data sources, where the data originated from and how it gets transformed and converged. Different personas in the data lake benefit from data lineage:
- For data scientists, the ability to view and track data flow as it moves from source to destination helps you easily understand the quality and origin of a particular metric or dataset
- Data platform engineers can get more insights into the data pipelines and the interdependencies between datasets
- Changes in data pipelines are easier to apply and validate because engineers can identify a job’s upstream dependencies and downstream usage to properly evaluate service impacts
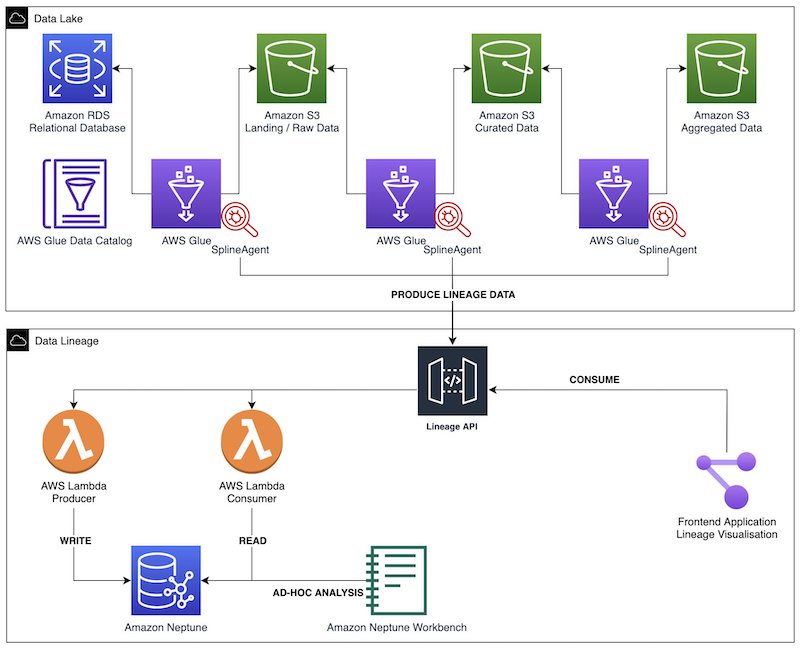
As the complexity of data landscape grows, customers are facing significant manageability challenges in capturing lineage in a cost-effective and consistent manner. In this post, we walk you through three steps in building an end-to-end automated data lineage solution for data lakes: lineage capturing, modeling and storage and finally visualization.
In this solution, we capture both coarse-grained and fine-grained data lineage. Coarse-grained data lineage, which often targets business users, focuses on capturing the high-level business processes and overall data workflows. Typically, it captures and visualizes the relationships between datasets and how they’re propagated across storage tiers, including extract, transform and load (ETL) jobs and operational information. Fine-grained data lineage gives access to column-level lineage and the data transformation steps in the processing and analytical pipelines.